
People Are Wrong About Google's Approach to AI Content
A case study of a website I launched just over a year ago and how it's performing now that gives an interesting perspective on AI, entity SEO, and where Google is right now post-March Core Update.

Near the end of 2022, me and a friend of mine decided to launch a new SEO project. We were both working for an agency at the time, and we wanted a place to experiment, try things, and “prove” that we knew what we were doing.
Perfect Extraction was the result of that idea—a specialty coffee blog that we hoped could rank for informational keywords and make money through affiliate sales and ad revenue.
We looked at the available niches, and given my previous life as a specialty coffee barista, we thought it was a great fit.
The competition was relatively low for the more long-tail keywords, and I had the subject matter expertise to differentiate us from a lot of similar sites.
What we didn’t anticipate was that between coming up with the idea and launching the site, OpenAI would launch ChatGPT.
GPT3 was pretty bad at writing content, and I have always been a writer. So I was hesitant to incorporate it at first.
But then we tried to launch the first couple of blogs in late January 2023. I had transitioned into a much more demanding role at the agency, and my time got limited.
I used GPT3 to help me outline my articles and suggest ideas, but I still wrote everything myself those first few months.
Within a couple of months, OpenAI launched GPT-4, and that completely changed how we approached the project.
It became a chance to test and try lots of different levels of AI assistance in content, from basic outlining, to optimizing, to full-on programmatic content.
The site gets just over 1,000 clicks a month now across 22 blog posts, with a little bit of digital PR done for backlinks.
I built the whole site on Webflow, and over the last year we tested a bunch of different things including:
AI-assisted blog posts
Experimental entity schema
Internal link experiments
User engagement tests on the SERP
And lastly—my first "programmatic" SEO project
This week, I just want to talk you through some of the things we tried—what worked, what didn’t work, and what I think you can learn from our experimentation to apply to your own projects.
And most importantly—I’ll explain why I think lots of people are wrong about AI content and Google.
What We Did
Putting aside the weird experimentation for a minute, there are two buckets we can use to categorize PE:
AI-assisted blogs
AI-generated programmatic pages.
I'll talk about these two things separately, as they're in different subfolders on the site and perform pretty differently, finalizing my conclusions at the end.
AI Blogs
From the very beginning, back in January of 2023, we were using AI to help outline blog posts. Almost all of them were created with AI and then edited by a human, with less than 3 being an exception to that rule.
The 3 below, in particular, are primarily AI-written, and yet they're the highest performing posts on the site—to this day. Despite there being genuine human-written content, as well (the how to make espresso article, for example, had no AI assistance at all).
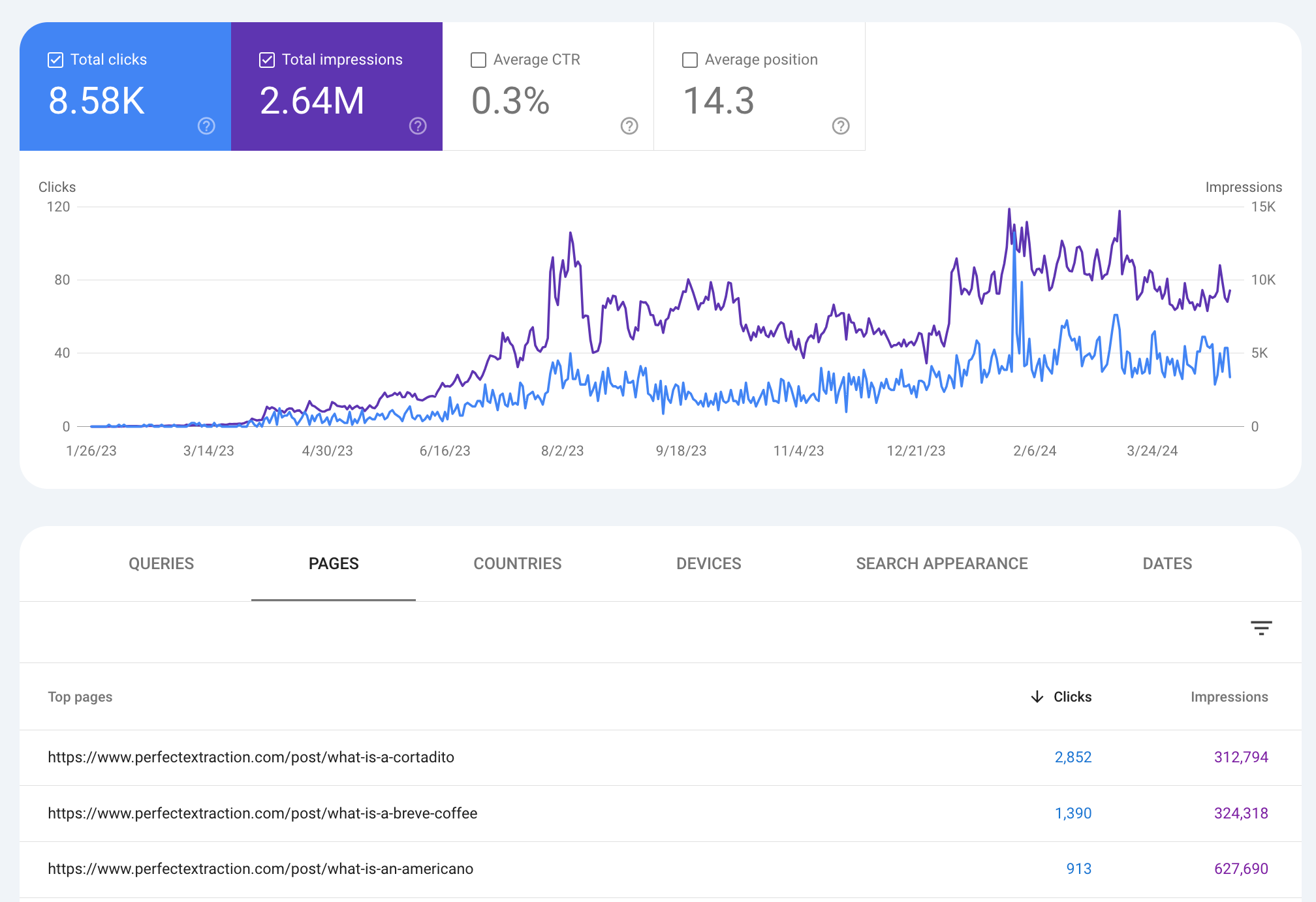
Without exception, content that was assisted by AI performs better than content that was written exclusively by a human.
Why Does The AI Content Perform Better?
This is a complicated question to answer, but I think it's a combination of three things.
Competition
Semantic/Entity Relevance
Human Editing
Competition
The competition levels for these keywords are lower than those we targeted with completely human-written content. Plain and simple.
Not that keyword difficulty is the best metric to use, but just as a proxy, our most "human" piece (how to make espresso) was around a 40, while all three of the key articles were less than 10 at the time we wrote them.
It’s not the only factor, but it is certainly a large piece of the puzzle.
Semantic/Entity Relevance
This may sound like nonsense at first, but hear me out on this.
Generally, LLMs can do a pretty good job of including semantically relevant information.
I don’t claim to be an expert by any means in LLM technology, but at a very basic level, they structure their data in a neural network—an interconnected graph of nodes that are placed next to similar nodes.
This is also the structure of Google's Knowledge Graph—an interconnected graph of nodes or “entities.”
We know things like topical and semantic content relevance are important to ranking—that’s not news. But in more recent years, there’s been a lot more thought and research put into this at the entity level rather than just thinking about keywords or natural language relevance.
My theory, for now, is that LLMs are better at understanding entities and what Google might see as relevant topics than a human would be.
Humans have been using tools like Clearscope, Surfer, and others to get closer to this “topical relevance” for years now, anyways, so I don’t think this is too crazy of a theory to propose.
In addition to using AI to create the content, we also tested some schema markup on these pages trying to double-down on these entity relationships.
I used an NLP analysis tool (in this case, Textrazor) to identify what entities were already present in the content on the site, and then I added some “sameAs” schema markup to the pages.
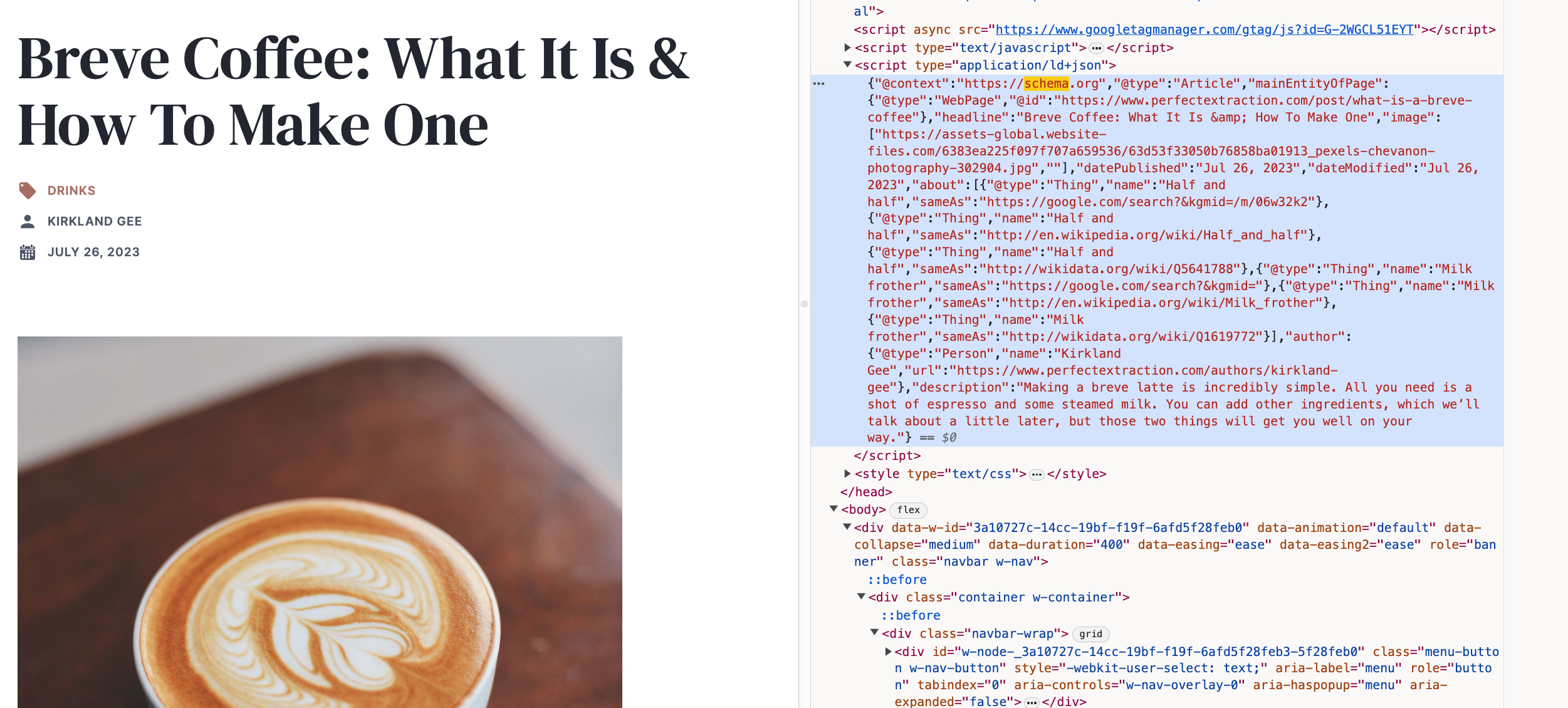
We did this programmatically, but you could also do this manually if you don't know how to write the code to do it for you.
Essentially, we just added an "about" section to our article schema, connecting this page to the relevant "entities" through Google's knowledge graph, wikidata, and wikipedia (not an entirely new idea, by any means, but trying to emphasize and test this idea).
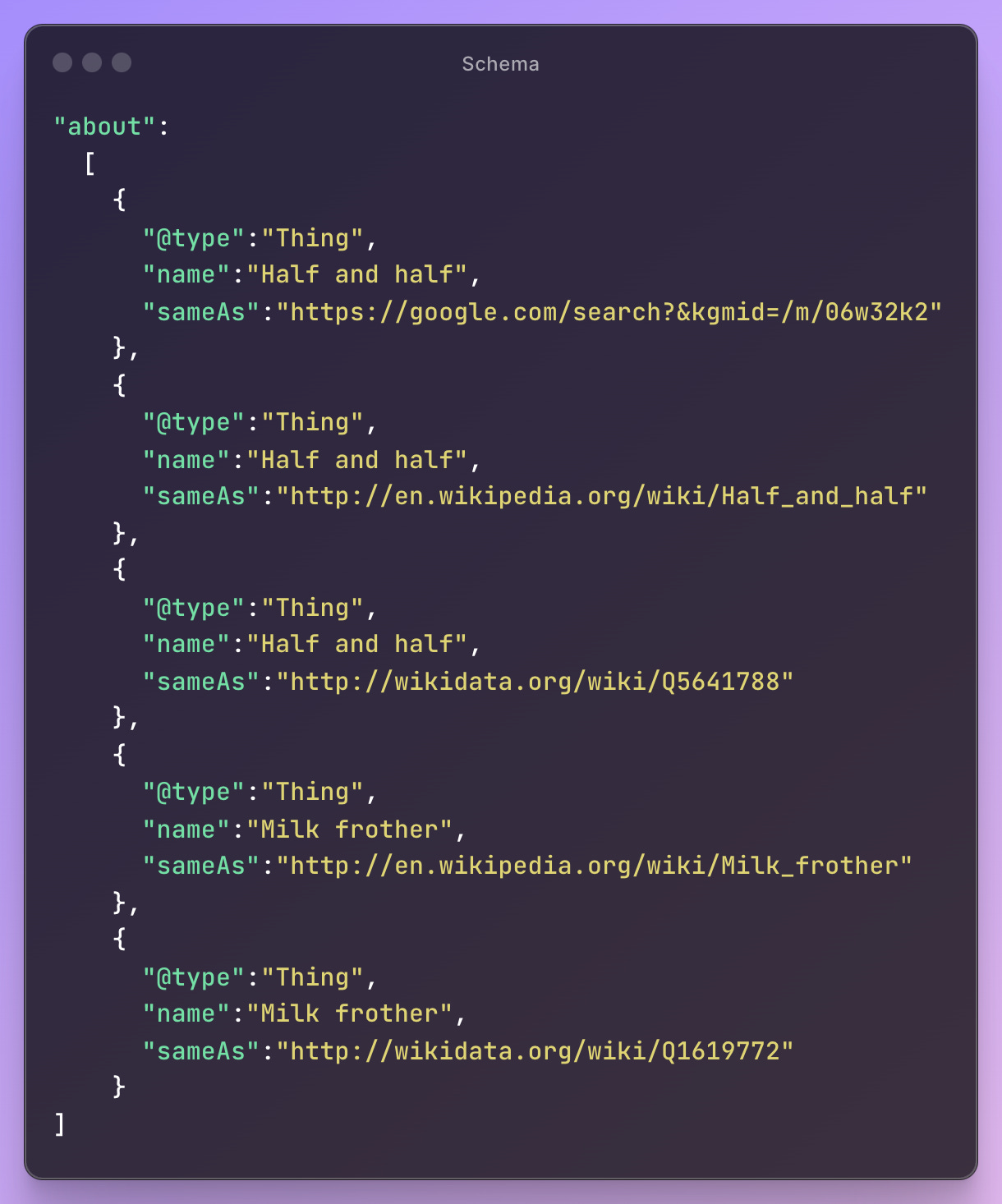
Between the content being structured by AI and some of these other relations, it appears to me that Google associates this page with the general entity of "Breve" more so than other articles on the same topic
Even though the content/domain may not be as high-quality as some of the competition, this article is actually the first non-dictionary/wiki result for searching just the term “breve”
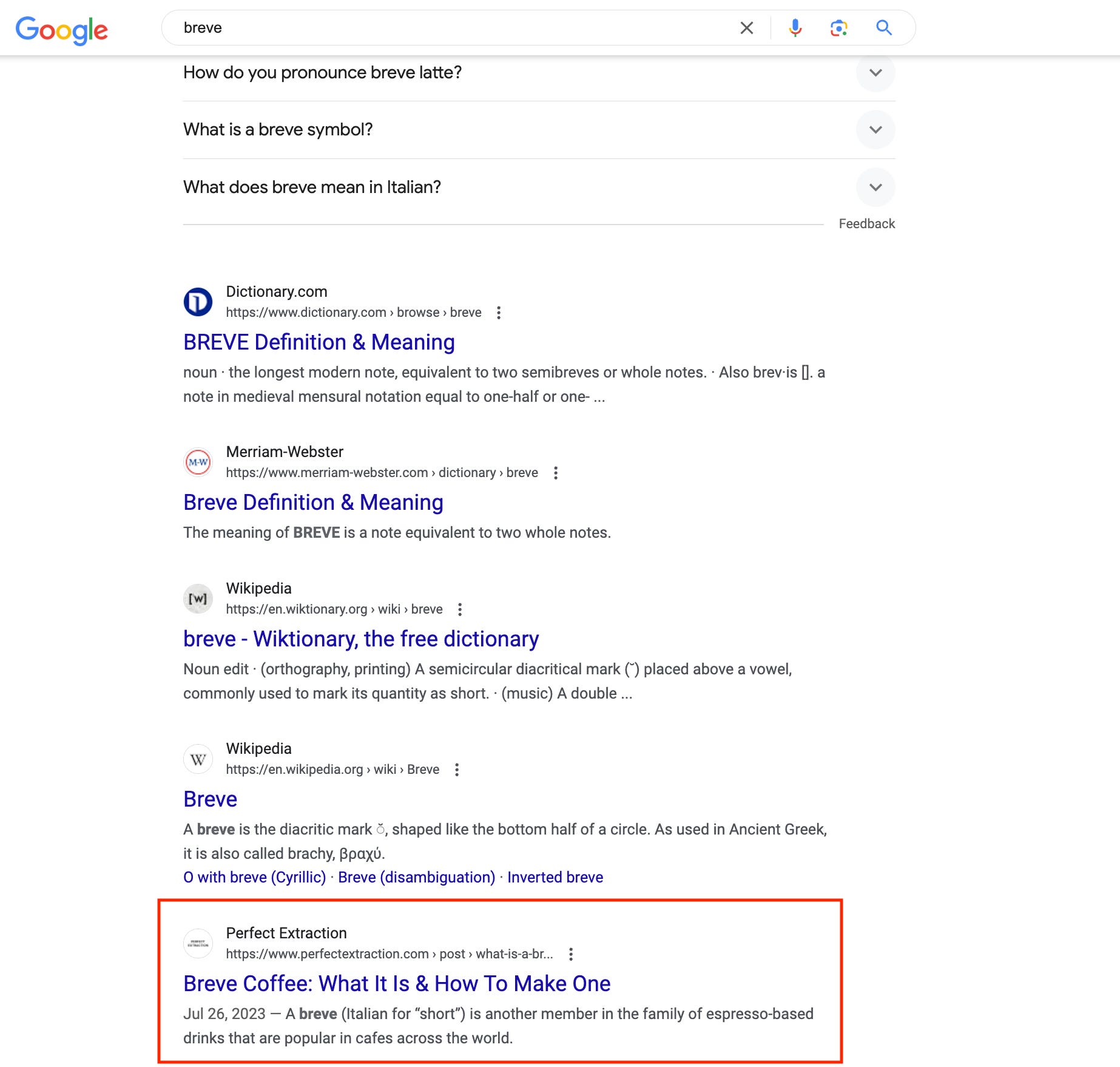
That could just be a coincidence, but I think it's indicative of some kind of knowledge graph relationship.
The article, interestingly, doesn't rank that high for it's target keyword "what is a breve". Again—could all be coincidence, but I think there's something going on with how Google sees the entity relationship.
My gut is that those entity signals are stronger than the content/domain signals, leading to the Google’s prioritization of our content on the more general term vs. the longer-tail question.
The Human Editing Was Very Good
Last and possibly most relevant—despite the fact that the bones of these articles were completely AI generated, we took a heavy editor's hand to the three that performed as well as they did.
Those we didn't never saw the same level of success, even if they would hover around a page one position.
Each of these was optimized with Clearscope by a human after the AI creation and normal human editing stage, as well.
The articles did rank prior to that Clearscope step, but they improved position after that.
TL;DR
These AI articles rank because they're not just "AI articles." They have been modified and tweaked enough that, for the low competition keywords they're targeting, they can compete with much higher quality domains.
Not to mention all of the other experimental work that was done—there's far too many factors for this to be a case study that says "AI content ranks." Although, I think the second part of this may provide some more insight into that.
Programmatic Content
I talked about this project a little bit in my piece on AI for Google Sheets, but I want to give a little more color on the nuts and bolts of it.
We created a list of ~150 different keywords related to specific coffee-growing regions all over the world. Then, I made a basic system prompt (with no additional info) and had GPT-4 write content related to each of those following a specific format.
I gave it three sections to write, but it had write them all at the same time. It led to some pretty obvious AI-isms, as well as likely some weird hallucinations.
My only input was "Ethiopia Koke" or whatever the region was with that basic system prompt.

I organized them all on a hub page with lots of internal links and let it fly.
In theory, these shouldn't have worked at all. They shouldn't get any traffic. They're purely search spam, mass produced with AI, meant to get traffic on Google, with no optimization after launch.
And yet—here's the data.
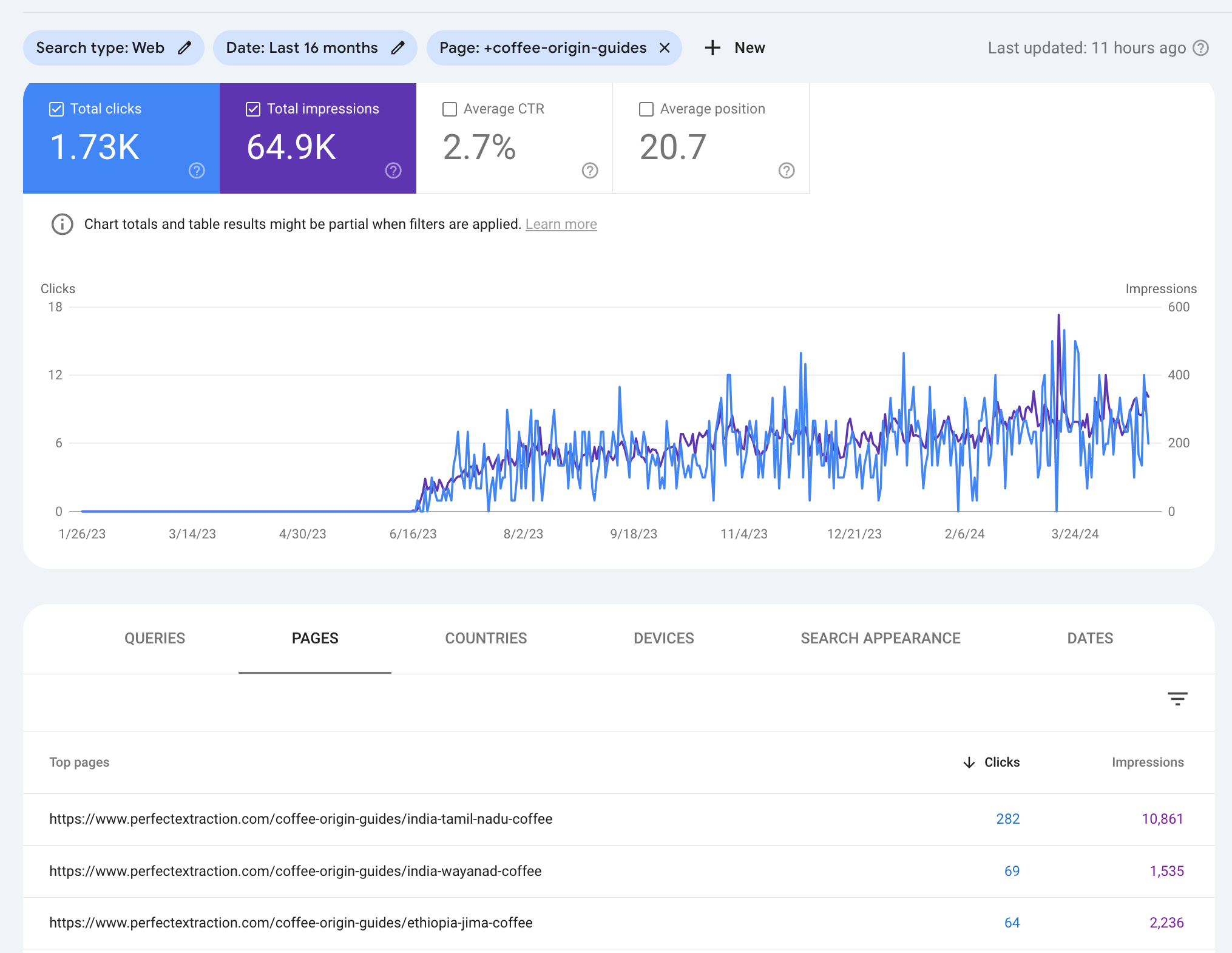
The traffic numbers are relatively low because these keywords are rarely searched at all. But these pages do rank for their specific target queries. And they rank well.
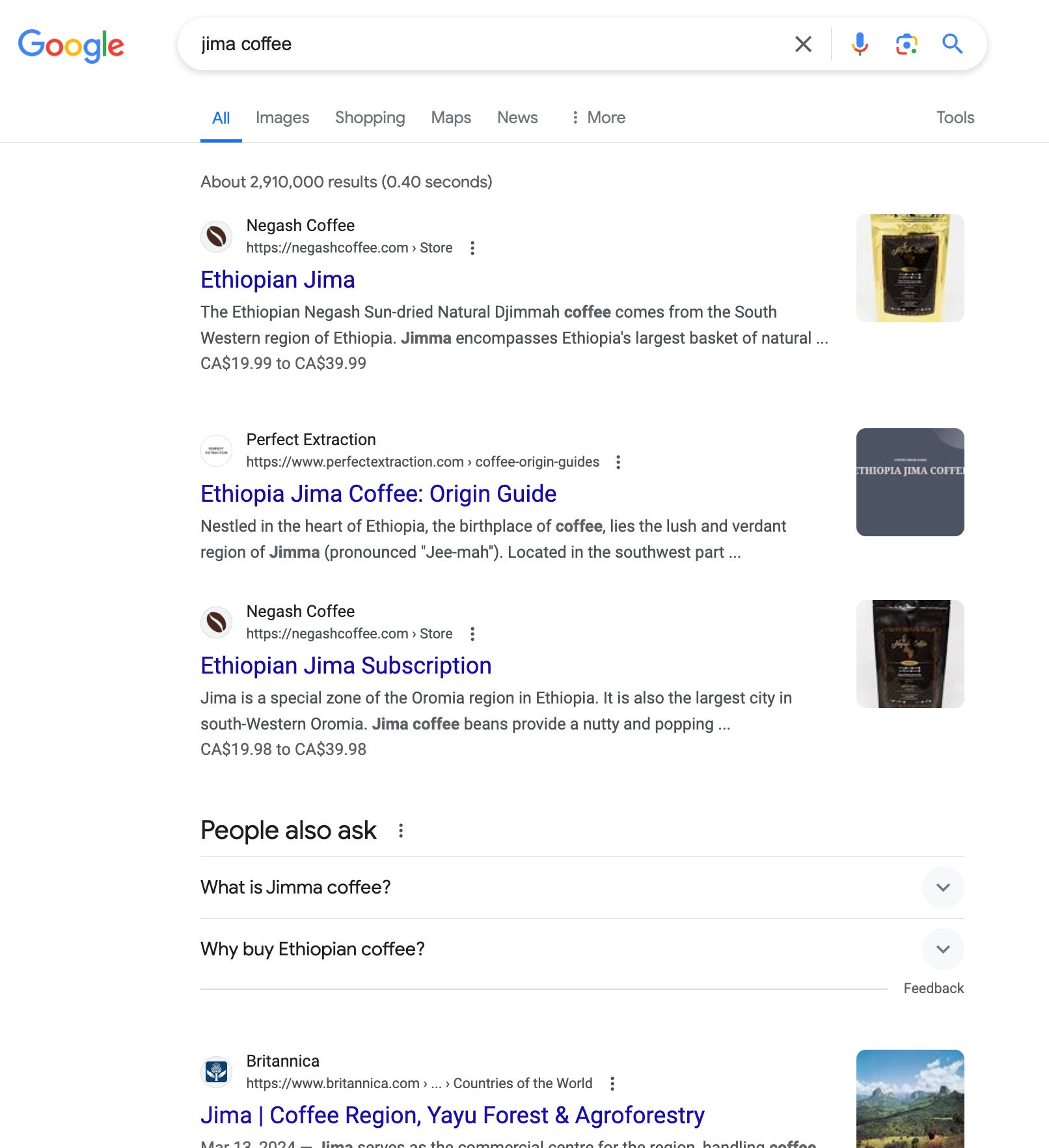
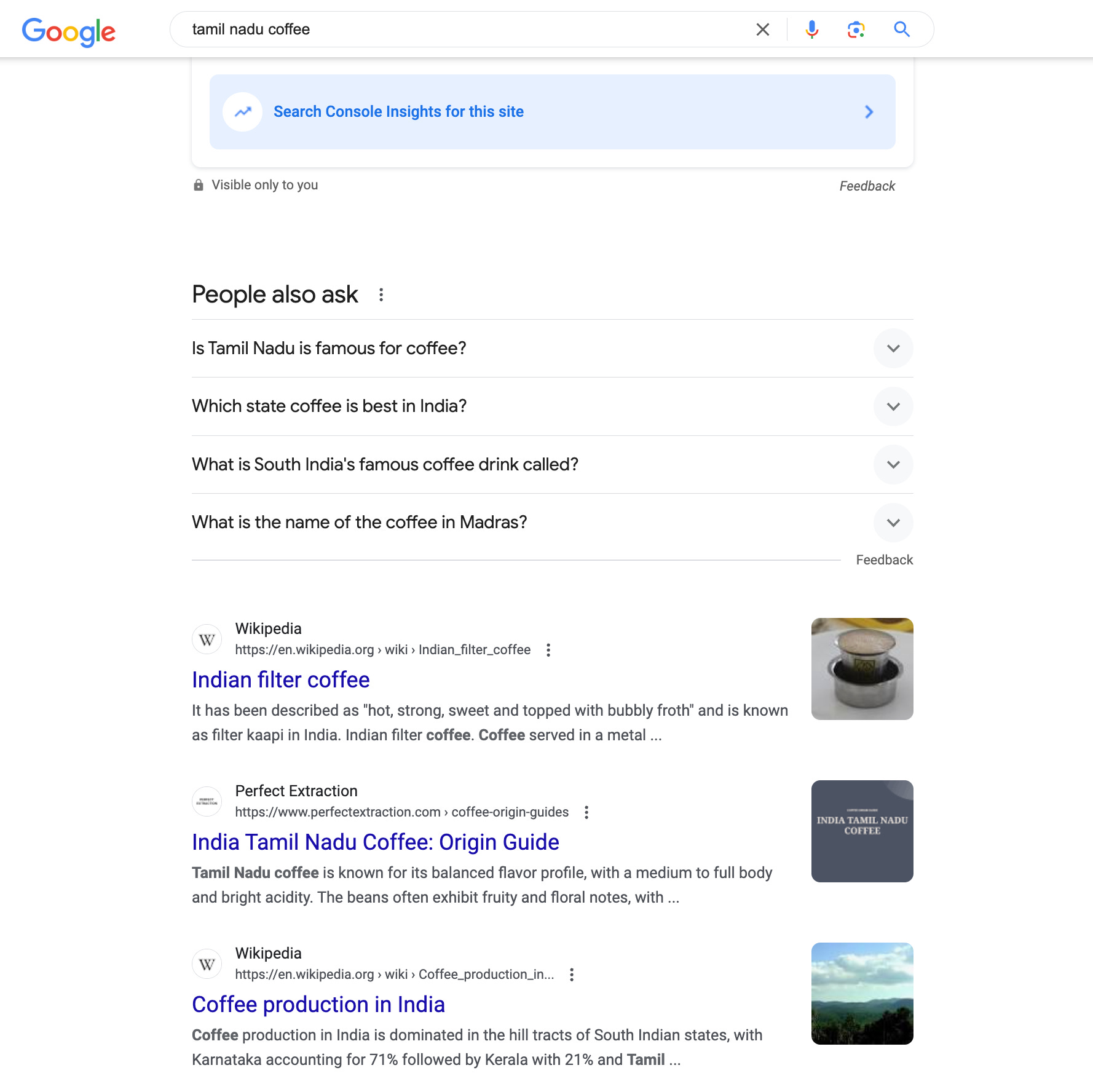
The most interesting part, to me, is that these pages have not been touched since July of 2023, and they gained traffic over the most recent Core Update. If Google were specifically targeting "AI content," you'd expect these pages to take a hit. But they didn't.
Why These Pages Still Rank
My theory as to why these pages still rank has very little to do with the quality of the pages themselves.
There's no original data or information, and a good chunk of the information is probably hallucinated (I haven’t even QA’d them enough to know for sure).
Instead, I think it says more about the quality of this most recent update than of these pages. I think this tells us that Google doesn't care whether content was written by AI.
What they are concerned about are the things we typically associate with AI content:
Spammy websites with bad UX
Intrusive ads
Lack of trust
The other options available to serve
My site, despite the content being pretty bad, ranks. And it saw almost 0 impact from the March core update. If anything, it saw a slight improvement.
My core hypothesis digging into this data is that the keywords are so niche that Google puts up with the terrible content because there's nothing else out there that serves that exact intent the same way.
From an analysis of a subset of of these pages, that seems to hold true. For this specific keyword set, there are two kinds of intent: purchase intent (buying coffee from that specific origin) and informational intent (learning about the region).
For a lot of these regions, Perfect Extraction is basically the only informational intent option.
Now–that may be no surprise. These are extremely niche keywords, and they don't get a lot of search volume. So why would anyone else create content to target them?
But there's a few bigger lessons to learn here, I think.
Lessons To Learn from Perfect Extraction
Below are the conclusions I think we can safely draw from this experiment.
You might have a case study that proves the opposite. If so—I'd love to hear about it—but for now, I'm focusing on what I can learn from this specific project.
1. Search Volume Doesn't Matter
The first lesson this case study can teach us is that, at this point, search volume should not be your priority when strategizing for SEO.
Saying it "doesn't matter" is hyperbolic, but it's getting at something that's true.
It's much more important that your content is useful and helpful to someone at their specific point in the user journey than that 100,000 people search for it every month. If you can't match intent, MSV won't matter.
And if you do, those 10 or 15 visitors could potentially make you more money than the 100,000.
This is old news now, but just because keywords show no volume in your KW research tool doesn't mean no one searches for them (this is an article making that case from 2022).
2. AI Content Can Rank (Sometimes)
It appears that this teaches us there are two occasions when AI content performs well.
When that content has been heavily modified
When there is little-to-no competition for the keywords you're targeting
In both of these scenarios, this AI content performs just fine—in fact, it outperforms expectations pretty significantly.
Take that into consideration as you plan how to use AI content in your own SEO projects.
3. Entities Matter
People buzz and talk a lot about "entity SEO" without really having a clear understanding of what the term even means (I was one of them at one point in time).
But if we look at this example, it's clear that, in some way, this stuff matters.
Google associates some of these articles much more closely with the core entities than higher-authority competition.
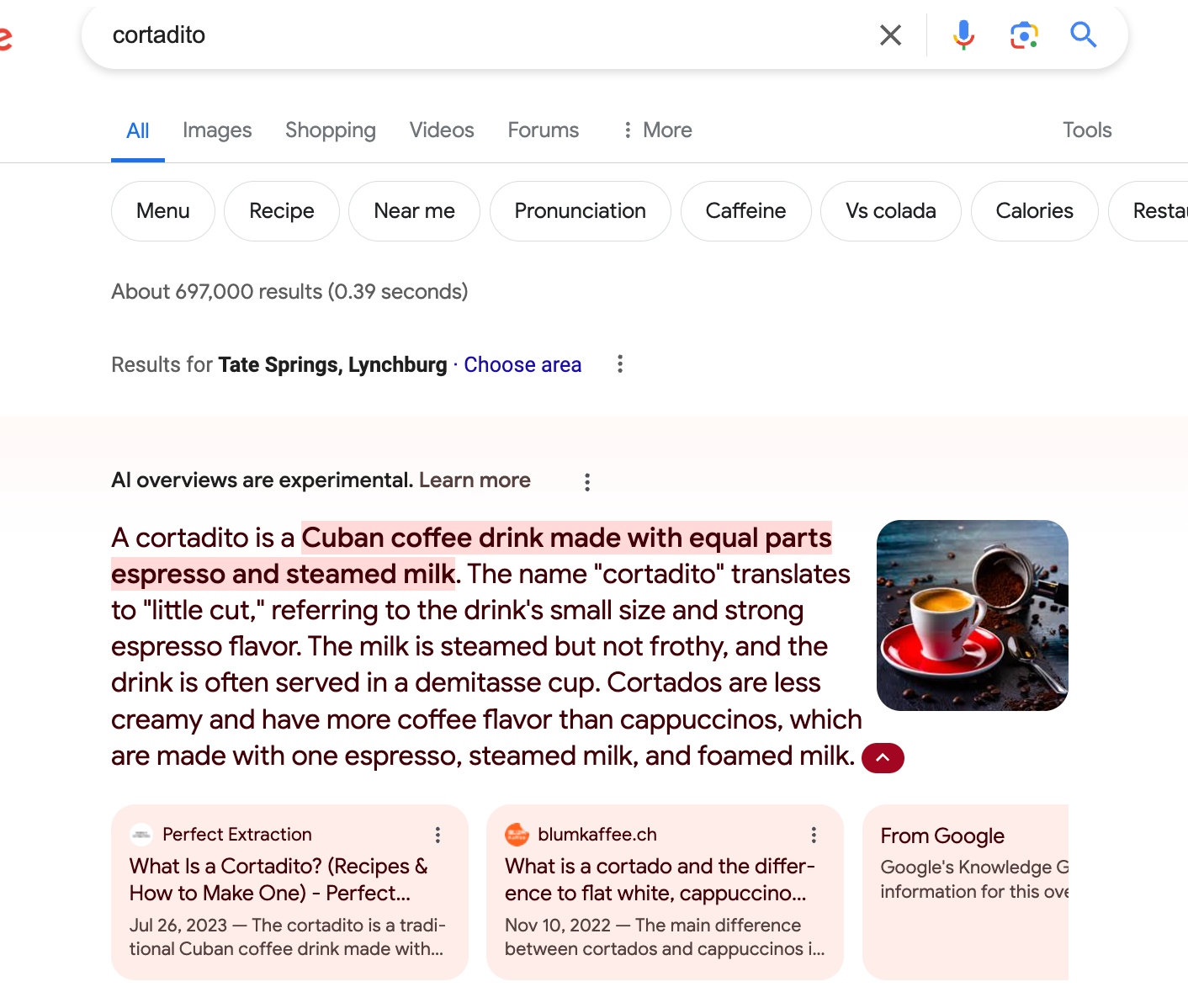
There's still some thinking to be done on how exactly this plays out for other scenarios, but it's clear that using AI and optimizing these pages for not just a keyword but the entity of "breve" or "cortadito" or whatever it may be was relevant to those pages' success.
A Final Word
If you got this far—thanks for reading! I love doing long-form stuff like this, and I hope you find it interesting.
If you have any ideas, thoughts, or opinions, I’d love to hear them. Hit me up here on Substack, shoot me an email—whatever.
This is just my best shot at interpreting some messy data, so I’d love to hear some competing perspectives.